Glyph-ByT5-v2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering













































Abstract
Recently, Glyph-ByT5 has achieved highly accurate visual text rendering performance in graphic design images, but it still focuses only on English and performs relatively poorly in terms of visual appeal. In this work, we address these two fundamental limitations by presenting Glyph-ByT5-v2, which not only supports accurate visual text rendering for 10 different languages but also achieves much better aesthetic quality.
To achieve this, we make the following contributions: (i) creating a high-quality multilingual glyph-text and graphic design dataset consisting of more than 1 million glyph-text pairs and 10 million graphic design image-text pairs covering nine other languages, (ii) building a multilingual visual paragraph benchmark consisting of 1,000 prompts, with 100 for each language, to assess multilingual visual spelling accuracy, and (iii) leveraging the latest step-aware preference learning approach to enhance the visual aesthetic quality.
With the combination of these techniques, we deliver a powerful customized multilingual text encoder, Glyph-ByT5-v2, and a strong aesthetic graphic generation model, Glyph-SDXL-v2, that can support accurate spelling in 10 different languages. We perceive our work as a significant advancement, considering that the latest DALLE-3 and Ideogram still struggle with the multilingual visual text rendering task.
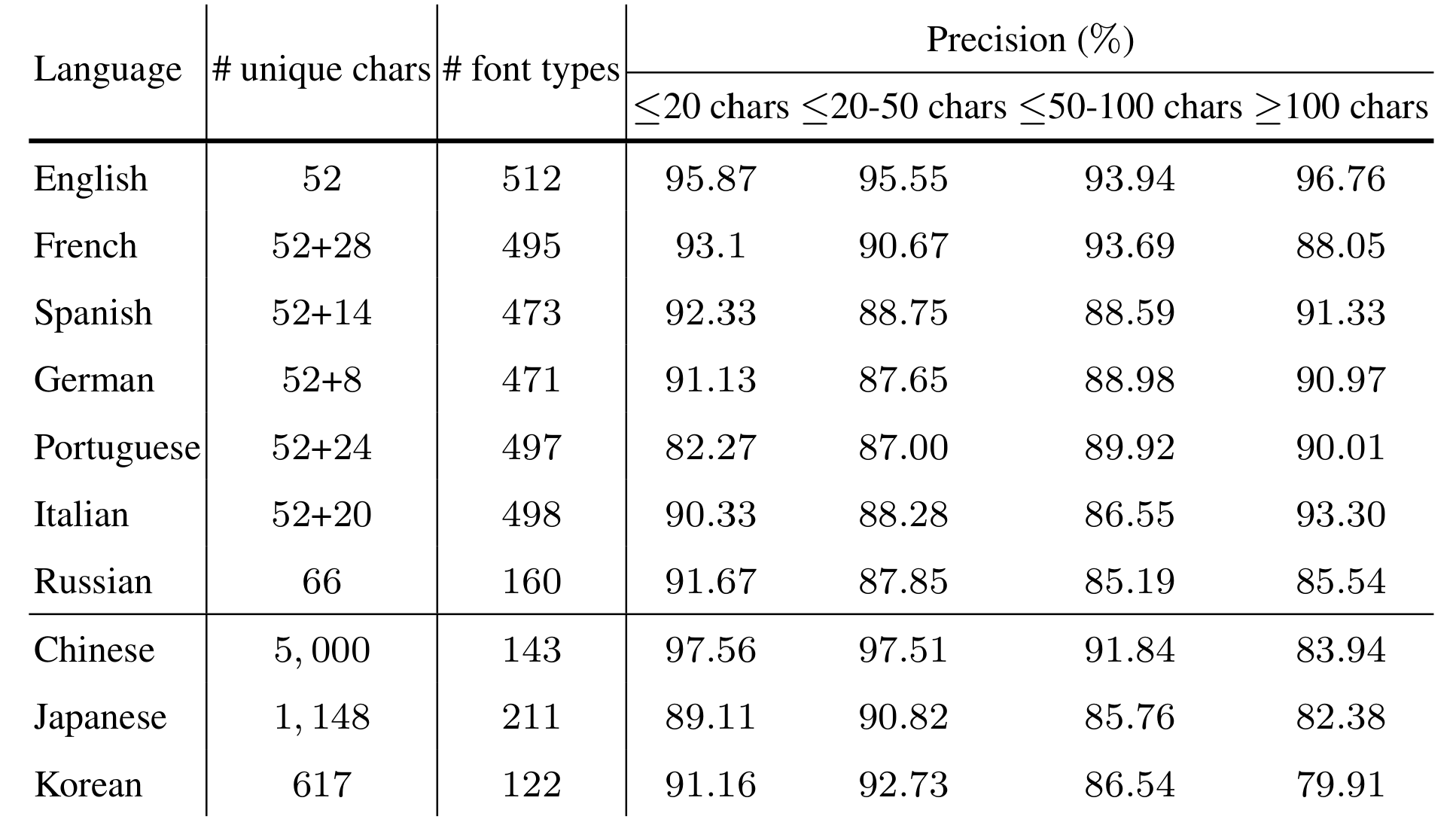
Improved multilingual visual text rendering precision
Improved aesthetics quality
User study results


Visualization results

















BibTeX
@article{liu2024glyphv2,
title={Glyph-ByT5-v2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering},
author={Liu, Zeyu and Liang, Weicong and Zhao, Yiming and Chen, Bohan and Li, Ji and Yuan, Yuhui},
journal={arXiv preprint arXiv:2406.10208},
year={2024}
}
@article{liu2024glyph,
title={Glyph-byt5: A customized text encoder for accurate visual text rendering},
author={Liu, Zeyu and Liang, Weicong and Liang, Zhanhao and Luo, Chong and Li, Ji and Huang, Gao and Yuan, Yuhui},
journal={arXiv preprint arXiv:2403.09622},
year={2024}
}